After the successful launch of a text-to-image model, a controversial launch of a text-to-music model, and a largely unnoticed launch of a text generation model, Stability AI has just announced the release of Stable Video Diffusion, a text-to-video tool that aims to carve a chunk out of the nascent generative video space.
"Stable Video Diffusion [is] a latent video diffusion model for high-resolution state-of-the-art text-to-video and image-to-video generation," Stability AI explains in the model’s research paper, and adds in the official announcement, “Spanning across modalities including image, language, audio, 3D, and code, our portfolio is a testament to Stability AI’s dedication to amplifying human intelligence."
This adaptability, coupled with open-source technology, paves the way for numerous applications in advertising, education, and entertainment. Stable Video Diffusion, which is now available in a research preview, is able to ”outperform image-based methods at a fraction of their compute budget," according to researchers.
Stable Video Diffusion's technical capabilities are impressive. "Human preference studies reveal that the resulting model outperforms state-of-the-art image-to-video models," the research paper reveals. Stability is clearly confident in the model's superiority in transforming static images into dynamic video content, saying its model beats closed models in user preference studies.
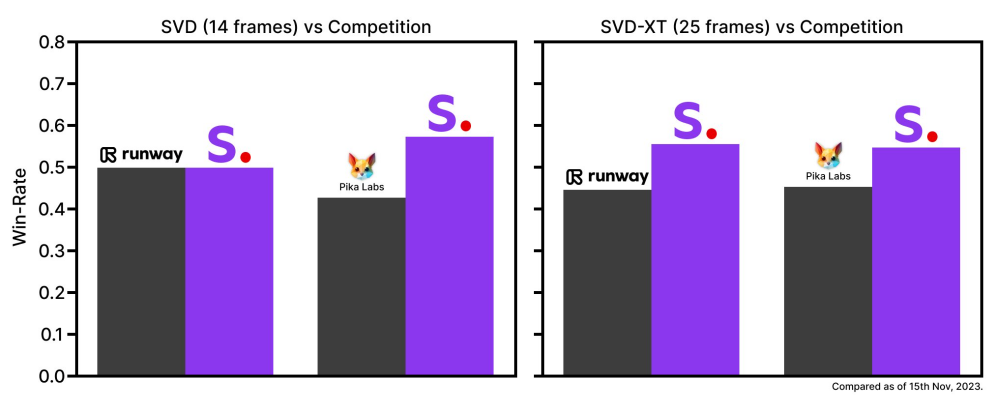
Stability AI has developed two models under the Stable Video Diffusion umbrella: SVD and SVD-XT. The SVD model transforms still images into 576×1024 videos in 14 frames, while SVD-XT uses the same architecture but extends to 24 frames. Both models offer video generation at frame rates ranging from three to 30 frames per second, sitting at the cutting-edge of open-source text-to-video technology.
In the rapidly evolving field of AI video generation, Stable Video Diffusion competes with innovative models like the ones developed by Pika Labs, Runway, and Meta. The latter's recently announced Emu Video, similar in its text-to-video capability, shows significant potential with its unique approach to image editing and video creation, albeit with a current limitation to 512x512 pixel resolution videos.
Despite its technological achievements, Stability AI is navigating through challenges, including ethical considerations around using copyrighted data in AI training. The company emphasizes that the model is "not intended for real-world or commercial applications at this stage," focusing on refining it based on community feedback and safety concerns.
Judging by the success of SD 1.5 and SDX—the most powerful open-source models for image generation—this new venture into the video generation scene hints at a future where the lines between the imagined and the real are not just blurred, but beautifully redrawn.
Edited by Ryan Ozawa.