
Алгоритм TurboQuant от Google Research обвалил акции производителей памяти: за несколько торговых сессий Micron Technology потеряла более 23 %, а совокупный рынок памяти просел примерно на 11 %.
24 марта 2026 года Google Research опубликовал анонс алгоритма TurboQuant — решения для сжатия данных на основе векторной квантизации. Авторы разработки — исследователь Амир Зандих (Amir Zandieh) и вице-президент Google Вахаб Мирроккни (Vahab Mirrokni). Алгоритм предназначен для сокращения объёма key-value (KV) кэша в больших языковых моделях — той самой «оперативной шпаргалки», которая хранит часто используемые данные и без которой современные LLM задыхались бы от нехватки памяти.
Как работает TurboQuant
Алгоритм сжимает KV-кэш как минимум в 6 раз, доводя объём данных до 3 бит на элемент, — и при этом не теряет точности ни на одном из протестированных бенчмарков, включая LongBench, Needle In A Haystack, ZeroSCROLLS и L-Eval. Не требует дообучения модели. На GPU NVIDIA H100 при 4-битной квантизации вычисление attention logits ускоряется до 8 раз по сравнению с 32-битным базовым вариантом.
В основе TurboQuant — два метода:
- PolarQuant: переводит координаты вектора из декартовых в полярные. Это убирает необходимость в дорогостоящей нормализации данных и позволяет хранить информацию компактнее — примерно как заменить «3 квартала на восток, 4 на север» на «5 кварталов под углом 37 градусов».
- QJL (Quantized Johnson-Lindenstrauss): использует всего 1 бит для устранения погрешности, которая остаётся после PolarQuant. Работает без дополнительных накладных расходов на память и позволяет точно рассчитывать оценку внимания (attention score) модели.
В совокупности это даёт систему, которая работает с эффективностью 3-битного хранилища при точности значительно более тяжёлых моделей. TurboQuant будет представлен на конференции ICLR 2026, а PolarQuant — на AISTATS 2026.
Рынок памяти отреагировал падением
Инвесторы восприняли анонс как угрозу для всей отрасли производства памяти. Если ИИ-системам потребуется в 6 раз меньше физической памяти для тех же задач, спрос на DRAM и HBM со стороны дата-центров может существенно снизиться — а именно этот сегмент в последние годы был главным драйвером роста для производителей чипов памяти.
Реакция рынка оказалась быстрой. За торговые сессии 25–27 марта 2026 года:
- Micron Technology (MU) — минус 23,02 % за шесть сессий;
- SanDisk (SNDK) — минус около 11 %;
- Samsung Electronics, SK Hynix и Kioxia — минус 5–6 % каждая;
- Seagate — снижение в диапазоне 4–6 %.
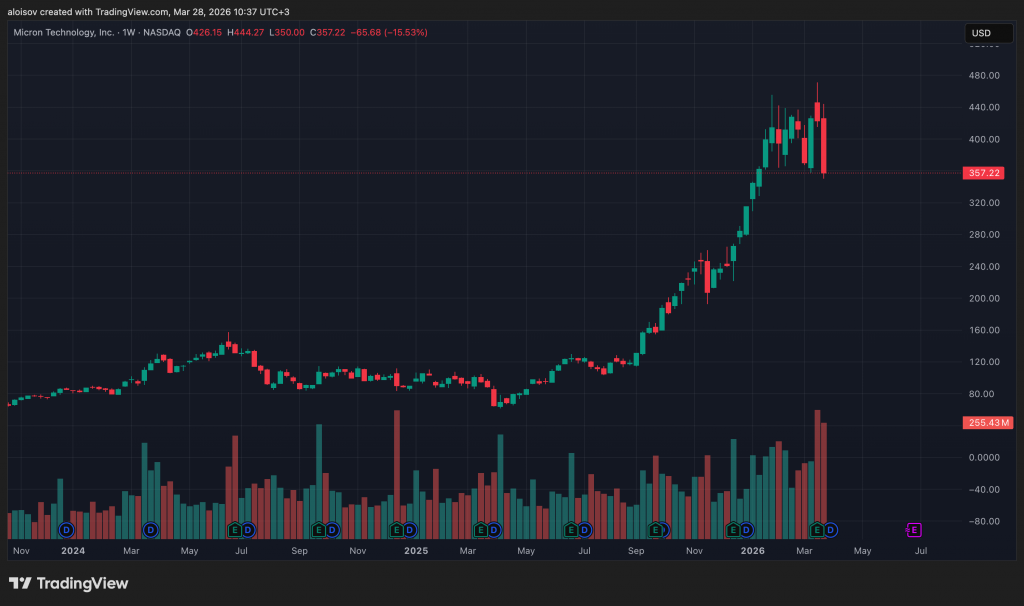
Совокупная капитализация ключевых игроков рынка памяти сократилась примерно на 11 %.
Контекст: эпоха дорогой памяти
Падение акций выглядит особенно примечательно на фоне того, что ещё недавно рынок памяти переживал ажиотажный рост. В начале 2025 года цены на DRAM и связанные компоненты взлетали на 200–400 % — во многом из-за масштабных закупок под ИИ-инфраструктуру. OpenAI в рамках проекта Stargate зарезервировала производственные мощности Samsung и SK Hynix на годы вперёд. Аналитики прогнозировали стабилизацию цен не ранее 2027 года.
TurboQuant меняет эту логику. Если алгоритм получит широкое распространение — а его авторы подчёркивают теоретически обоснованную близость к оптимуму, — потребность в физической памяти для ИИ-задач может оказаться значительно скромнее, чем закладывалось в инвестиционные модели последних двух лет.
Google позиционирует разработку не только как инструмент для LLM, но и как основу для ускорения векторного поиска — технологии, на которой работают поисковые системы и рекомендательные алгоритмы в масштабе сотен миллиардов векторов. Алгоритм уже тестировался на открытых моделях Gemma и Mistral, а его применимость к Gemini упоминается в числе ключевых направлений.
Мнение ИИ
Исторический паттерн здесь узнаваем. В январе 2025 года выход DeepSeek R1 обвалил Nvidia на $600 млрд капитализации за один день — и та восстановилась за несколько недель, когда выяснилось, что реальный спрос на чипы никуда не делся. TurboQuant бьет по другому сегменту, но механика рыночной реакции та же: инвесторы сначала продают, потом считают.
Техническая деталь, которую стоит учитывать: TurboQuant сокращает KV-кэш при инференсе — то есть при запуске уже обученных моделей. Однако обучение новых LLM по-прежнему требует колоссальных объемов HBM-памяти, и этот спрос алгоритм не затрагивает. Иными словами, угроза реальна для серверного инференса, но не для всей цепочки ИИ-инфраструктуры. Устоит ли нынешняя коррекция акций производителей памяти или повторит судьбу «шока от DeepSeek» — покажет то, насколько быстро TurboQuant выйдет за рамки академической публикации.