
Данные — это кровеносная система физического ИИ. Без них автономный автомобиль, дрон или боевой робот не сделают и шага. Но собирать эти данные в реальном мире — занятие дорогостоящее, долгое и физически опасное. Стартап DiffuseDrive предлагает иной путь: генерировать реалистичные синтетические данные с помощью диффузионных моделей — и делать это в промышленных масштабах.
Цена реального опыта
Компания Waymo, прежде чем запустить полноценный сервис беспилотного такси в Сан-Франциско в 2024 году, собирала данные на дорогах Калифорнии 15 лет — начиная с 2010-го, когда ее материнская структура Google впервые выехала на тест. За это время накопилось около 20 млн миль реальных поездок. Стоимость такого проекта приближается к миллиарду долларов. Именно этот барьер делает рынок автономного вождения практически закрытым для новичков.
Аналогичная проблема стоит перед разработчиками физического ИИ в строительстве, сельском хозяйстве, горнодобывающей отрасли, на железных дорогах, в морской и авиационной сфере. Везде нужны данные: разнообразные, охватывающие редкие и критические сценарии — те самые «длинные хвосты» распределения, на которых системы чаще всего и ошибаются.
Синтетика против реальности
Калифорнийский стартап DiffuseDrive (DD) основан в 2023 году выходцами из Bosch — генеральным директором Балинтом Пастором (Bálint Pásztor) и техническим директором Роландом Пинтером (Roland Pintér). В 2024–2025 годах компания привлекла $5 млн: $4 млн в рамках посевного раунда от Outlander, Presto Tech Horizons и NeuronVC, а также более ранние инвестиции от E2VC. В штате — 12 человек, четверо из которых работают в США, восемь — в Европе.
Компания направлена на рынок синтетических визуальных данных, который сейчас оценивается примерно в $425 млн, а к 2030 году, по прогнозам аналитиков, вырастет до $2 млрд.
Суть подхода DD — взять реальные данные заказчика (видео и изображения с камер, уже размеченные), провести их статистический анализ и на этой основе сгенерировать тысячи и миллионы синтетических сцен, которые никогда не встречались в реальном мире, но статистически достоверны.
Как это работает
Процесс начинается с анализа данных клиента по нескольким направлениям:
- Анализ размеров ограничивающих рамок — определяет, насколько хорошо в данных представлены близкие и далекие объекты.
- Анализ распределения центральных точек — выявляет, достаточно ли представлены объекты на краях кадра.
- Кластеризация и покрытие пространства признаков — показывает, где данных в избытке, а где — белые пятна.
- Матрица совместной встречаемости — измеряет, как часто разные классы объектов появляются в одном кадре, что помогает обнаружить редкие и критически важные комбинации.
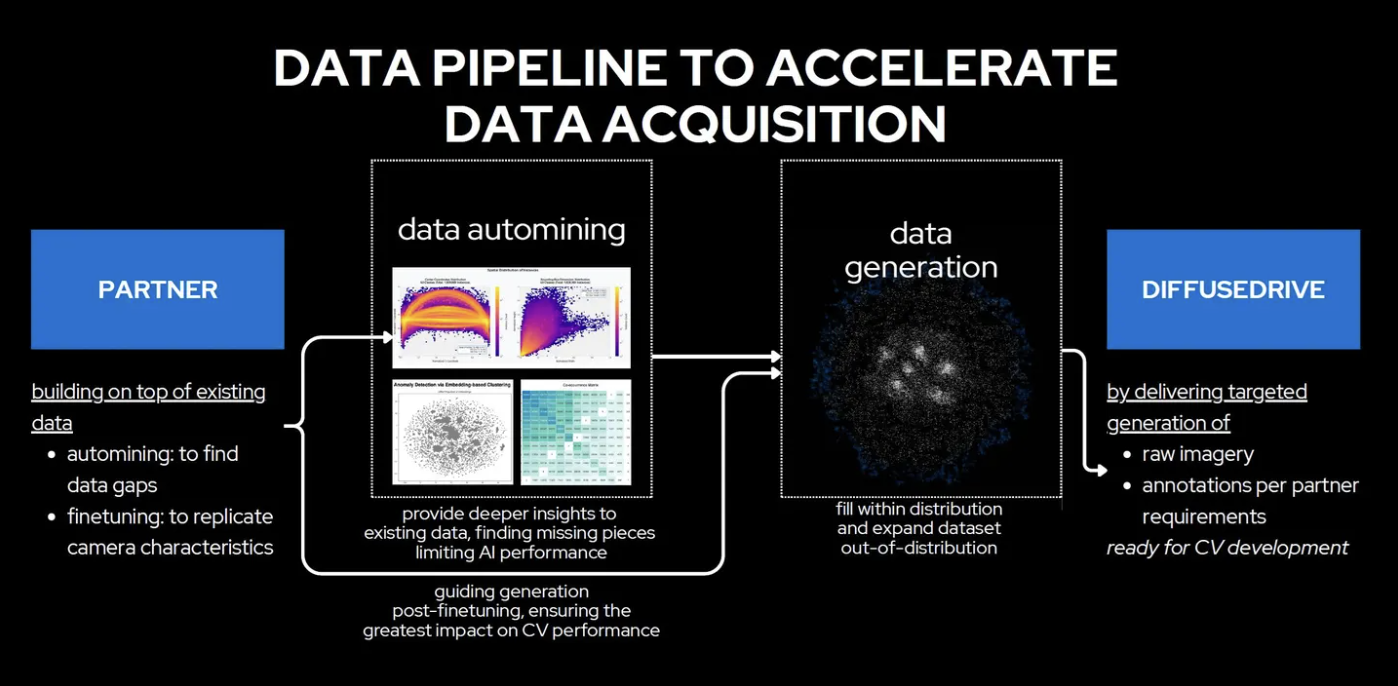
После того как пробелы выявлены, в дело вступают диффузионные модели. Эта технология, лежащая в основе современных генеративных систем, работает так: в исходные изображения постепенно вносится случайный шум, а затем он методично устраняется — и на выходе получается новое высококачественное синтетическое изображение. Большие языковые модели (LLM) выступают в роли «режиссеров»: они переводят пользовательские запросы в структурированные текстовые описания, которые направляют диффузионную модель к нужному результату.
Клиент может задать диапазоны параметров среды — рельеф, погода, освещение, время суток, — указать типы объектов и их взаимодействие, а также запросить редкие конфигурации: например, тигра на шоссе или проливной дождь, при котором камеры едва функционируют. Все сгенерированные данные размечаются автоматически — на основе параметров, заданных при описании сценария.
Тест на реальных данных
Чтобы доказать ценность своего подхода, DD провела эксперимент на подмножестве открытого датасета DOTA, широко используемого в компьютерном зрении. Из него были извлечены 2 961 реальное изображение с воздушными судами: 93% — самолеты, 7% — вертолеты.
При обучении нейросети только на реальных данных с таким классовым дисбалансом распознавание вертолетов оказалось неудовлетворительным. Добавление синтетических изображений от DD для балансировки классов резко улучшило показатели распознавания вертолетов. При объединении всех реальных и синтетических данных качество распознавания существенно выросло по обоим классам.
Кто уже работает с DD
Среди клиентов стартапа — крупный мировой поставщик автокомплектующих и американский оборонный подрядчик, хотя их названия пока не раскрываются.
Автопроизводитель использует синтетические данные DD для обучения систем ADAS (систем помощи водителю) и автономного вождения. Отдельный бонус: синтетические данные по умолчанию соответствуют европейскому регламенту GDPR о защите персональных данных — в отличие от реальных съемок, которые требуют ручного удаления номерных знаков и геолокационной информации.
Оборонный подрядчик, с которым DD начала сотрудничество в четвертом квартале 2025 года, занимается обработкой сенсорных и GPS-данных с военных платформ — наземных, воздушных и морских. Задача — строить карты восприятия, распознавать угрозы и координировать автономное движение активов в условиях радиопомех и противодействия противника. Для этого DD анализирует спутниковые снимки зон конфликтов и генерирует на их основе синтетические обучающие сценарии с иерархической разметкой объектов: самолеты, вертолеты, танки, корабли — с детальной классификацией внутри каждой группы.
Физический ИИ упирается в данные — и это узкое место тормозит всю отрасль. DiffuseDrive предлагает способ его расшить: генерировать синтетические данные с автоматической разметкой, масштабируемо и без колоссальных затрат на полевые испытания. Компания работает сразу в нескольких секторах — от гражданской автоматики до военных применений, — что дает ей возможность накапливать кросс-отраслевую экспертизу и снижать зависимость от успеха в какой-либо одной нише.
Мнение ИИ
С точки зрения машинного анализа данных, история технологических переходов показывает любопытную закономерность: каждый раз, когда стоимость производства ключевого ресурса резко падает, рынок не просто растет — он структурно меняется. Синтетические данные сейчас находятся примерно там, где облачные вычисления были в 2008–2010 годах: нишевый инструмент для избранных стремительно превращается в базовую инфраструктуру. Но есть нюанс, который статья не затрагивает: проблема ’distribution shift‘ — расхождения между синтетическим распределением данных и реальным миром. Нейросеть, обученная на идеально сбалансированной синтетике, может деградировать при столкновении с хаосом реальности именно там, где ее никто не тестировал.